Atmospheric Retrievals¶
Contents
Below, we demonstrate the use of ExoCTK’s platon_wrapper module. As suggested by its name, this module is a wrapper around the platon.retreiver.run_multinest and platon.retriever.run_emcee methods, which uses multinested sampling and MCMC algorithms to retrieve atmospheric parameters, respectively. For further information about platon, see the project documentation, the API docs for the retriever module, or the GitHub repository.
Note that some of the examples provided below are minimal, bare-bones examples that are meant to show how users may use the software while not taking much computation time to complete. The parameters used and the corresponding results are not indiative of a true scientific use case. For more comprehensive and robust examples, see the examples.py module in the exoctk.atmospheric_retrievals subpackage.
The first section of this page provides a simple example of how to run the software on a local machine. The later sections describe how to perform retrievals using Amazon Web Services (AWS) Elastic Computing (EC2) instances.
This notebook assumes that the user has installed the exoctk package and its required libraries. For more information about the installation of exoctk, see the installation instructions.
A Simple Example¶
Below is a simple example of how to use the PlatonWrapper object to perform atmospheric retrievals. First, a few necessary imports:
import numpy as np
from platon.constants import R_sun, R_jup, M_jup
from exoctk.atmospheric_retrievals.platon_wrapper import PlatonWrapper
The PlatonWrapper object requires the user to supply a dictionary containing initial guesses of parameters that they wish to fit. Note that Rs, Mp, Rp, and T must be supplied, while the others are optional.
Also note that Rs are in units of solar radii, Mp are in units of Jupiter masses, and Rp is is units of Jupiter radii.
params = {
'Rs': 1.19, # Required
'Mp': 0.73, # Required
'Rp': 1.4, # Required
'T': 1200.0, # Required
'logZ': 0, # Optional
'CO_ratio': 0.53, # Optional
'log_cloudtop_P': 4, # Optional
'log_scatt_factor': 0, # Optional
'scatt_slope': 4, # Optional
'error_multiple': 1, # Optional
'T_star': 6091} # Optional
In order to perform the retrieval, users must instantiate a PlatonWrapper object and set the parameters.
pw = PlatonWrapper()
pw.set_parameters(params)
Users may define fitting priors via the fit_info attribute.
pw.fit_info.add_gaussian_fit_param('Mp', 0.04*M_jup)
pw.fit_info.add_uniform_fit_param('Rp', 0.9*(1.4 * R_jup), 1.1*(1.4 * R_jup))
pw.fit_info.add_uniform_fit_param('T', 300, 3000)
pw.fit_info.add_uniform_fit_param("logZ", -1, 3)
pw.fit_info.add_uniform_fit_param("log_cloudtop_P", -0.99, 5)
Prior to performing the retrieval, users must define bins, depths, and errors attributes. The bins atribute must be a list of lists, with each element being the lower and upper bounds of the wavelenth bin. The depths and errors attributes are both 1-dimensional numpy arrays.
wavelengths = 1e-6*np.array([1.119, 1.1387])
pw.bins = [[w-0.0095e-6, w+0.0095e-6] for w in wavelengths]
pw.depths = 1e-6 * np.array([14512.7, 14546.5])
pw.errors = 1e-6 * np.array([50.6, 35.5])
With everything defined, users can now perform the retrieval. Users may choose to use the the MCMC method (emcee) or the Multinested Sampling method (multinest).
MCMC Method
pw.retrieve('emcee')
pw.save_results()
pw.make_plot()
Multinested Sampling Method
pw.retrieve('multinest')
pw.save_results()
pw.make_plot()
Note that results are saved in a text file named <method>_results.dat, a corner plot is saved to <method>_corner.png, and a log file describing the execution of the software is saved to YYYY-MM-DD-HH-MM.log, which is a timestamp reflecting the creation time of the log file.
Using Amazon Web Services to Perform Atmospheric Retrievals¶
The following sections guide users on how to perform atmospheric retrievals using Amazon Web Services (AWS) Elastic Computing (EC2) instances.
What is Amazon Web Services?¶
Amazon Web Services provides on-demand cloud-based computing platforms, with a variety of services such as Elastic Compute Cloud (EC2), Cloud Storage (S3), Relational Database Service (RDS), and more. Learn more at https://aws.amazon.com/what-is-aws/
What is an EC2 Instance?¶
The Elastic Compute Cloud (EC2) service enables users to spin up virtual servers, with a variety of operating systems, storage space, memory, processors. Learn more at https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/concepts.html
Why use AWS?¶
Atmospheric retrievals are often computationally expensive, both in the amount of time it takes to complete a retrieval, but also in the cost of purchasing and/or maintaining a suitable machine. Particularly, if users do not have access to a dedicated science machine or cluster, and instead must rely on personal laptops or desktops, atmospheric retrievals can become quite burdensome in day-to-day research work.
AWS provides a means to outsource this computational effort to machines that live in the cloud, and for low costs. With AWS, users can create a virtual machine (VM), perform atmospheric retrievals, and have the machine automatically shutdown upon completion. Depending on the type of VM, typical costs can range from anywhere between ~\$0.02/hour (i.e. a small, 1 CPU Linux machine) to ~\$3.00/hour (i.e. a heftier, multiple CPU, GPU-enabled Linux machine).
For example, a small trial run of an atmospheric retrieval for hd209458b using PLATON takes roughly 35 minutes at a total cost of \$0.01 using a small CPU EC2 instance, and took roughly 24 minutes at a total cost of \$1.22 using a GPU-enabled EC2 instance.
AWS-specific software in the atmospheric_retrievals subpackage¶
The atmospheric_retrievals subpackage provides software that enables users to use AWS EC2 instances to perform atmospheric retrievals. The relevant software modules/tools are:
aws_config.json- a configuration file that contains a path the a public ssh key and a pointer to a particular EC2 instanceaws_tools.py- Various functions to support AWS EC2 interactivity, such as starting/stopping an EC2 instance, transferring files to/from EC2 instances, and logging standard output from EC2 instancesbuild-exoctk-env-cpu.sh- A bash script for creating anexoctksoftware environment on an EC2 instancebuild-exoctk-env-gpu.sh- A bash script for creating anexoctksoftware environment on a GPU-enabled EC2 instanceexoctk-env-init.sh- A bash script that initializes an existingexoctksoftware environment on an EC2 instance
Setting up an AWS account¶
Users must first set up an AWS account and configure a ssh key pair in order to connect to the services.
Visit https://aws.amazon.com to create an account. Unfortunately, a credit card is required for sign up. There is no immediate fee for signing up; users will only incur costs when a service is used.
Once an account has been created, sign into the AWS console. Users should see a screen similar to this:
At the top of the page, under “Services”, select “IAM” to access the Identity and Access Management console.
On the left side of the page, select “Users”
Click the “Add user” button to create a new user. In the “User name” field, enter the username used for the AWS account. Select “Programmatic access” for the “Access type” option. Click on “Next: Permissions”.
Select “Add user to group”, and click “Create group”. A “Create group” pane will open. In the “Group name” field, enter “admin”. Check the box next to the first option, “AdministratorAccess”, and click “Create group”.
Click “Next: Tags”. This step is optional, so users may then click “Next: Review”, then “Create user”.
When the user is created, users will be presented with a “Access Key ID” and “Secret Access Key”. Take note of these, or download them to a csv file, as they will be used in the next step.
In a terminal, type
aws configure. Users will be prompted to enter their Access Key ID and the Secret Access Key from the previous step. Also provide a Default region name (e.g.us-east-1,us-west-1, etc.) and for “output format” usejson. For a list of available region names, see https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Concepts.RegionsAndAvailabilityZones.htmlExecuting these commands should result in the creation of a
aws/directory, containingconfigandcredentialsfiles populated with the information that was provided.
Create a SSH key pair¶
In order to connect to an EC2 instance, users must next configure an SSH key pair:
In a terminal, type
ssh-keygen -t rsa -f, where<rsa_key_name>is the name of the resulting ssh key files (users can name this whatever they would like). When prompted to enter a passphrase, leave it empty by hittingenter, and thenenteragain. Running this command should result in the creation of two files: (1)<rsa_key_name>, which is the private SSH key, and<rsa_key_name>.pub, which is the public SSH key.In the browser, navigate to the AWS EC2 console (https://console.aws.amazon.com/ec2), select
Key PairsunderNetwork & Securityon the left hand side of the page.Select
Import key pairIn the
Namefield, enter a name you wish to use.In the large field on the bottom, paste the contents of the
<rsa_key_name>.pub file.Select
Import key pairto complete the process.
Launch an EC2 instance¶
To create and launch an EC2 instance:
Select “Instances” from the left-hand side of the AWS EC2 console
Select the “Launch Instance” button
Select an Amazon Machine Image (AMI) of your choosing. Note that there is a box on the left that allows users to only show free tier only eligible AMIs. For the purposes of the examples in this notebook, it is suggested to use
ami-0c322300a1dd5dc79(Red Hat Enterprise Linux 8 (HVM), SSD Volume Type, 64-bit (x86)).Select the Instance Type with the configuration of your choosing. For the purposes of the examples in this notebook, it is suggested to use
t2.small. When satisfied, choose “Review and Launch”On the “Review Instance Launch” page, users may review and/or change any settings prior to launching the EC2 instance. For the purposes of the examples in this notebook, it is suggested to “Edit storage” and increase the “Size” to 20 GiB to allow enough storage space to build the
exoctksoftware environment.When satisfied, click “Launch”. The user will be prompted to select or create a key pair. Select the existing key pair that was created in the “Create a SSH key pair” section. Check the acknowledgement box, and select “Launch Instances”
If the EC2 instance was launched successfully, there will be a success message with a link to the newly-created EC2 instance.
Note: For users interested in using GPU-enabled EC2 instances, see the “Using a GPU-enabled EC2 instance” section at the end of this notebook. This warrants its own section because it requires a rather complex installation process.
Build the exoctk software environment on the EC2 instance¶
Once the newly-created EC2 instance has been in its “Running” state for a minute or two, users can log into the machine through the command line and install the necessary software dependencies needed for running the atmospheric_retrievals code.
To log into the EC2 instance from the command line, type:
ssh -i <path_to_private_key> ec2-user@<ec2_public_dns>
where <path_to_private_key> is the path to the private SSH key file (i.e. the <rsa_key_name> that was created in the “Create a SSH key file” section), and <ec2_public_dns> is the Public DNS of the EC2 instance, which is provided in the “Description” of the EC2 instance under the “Instances” panel in the AWS EC2 console. This public DNS should look something like ec2-NN-NN-NNN-NN.compute-N.amazonaws.com.
Users may be asked (yes/no) if they want to connect to the machine. Enter “yes”.
Once logged in, users can build the exoctk software environment by either copy/pasting the commands from the atmospheric_retrievals/build-exoctk-env-cpu.sh file straight into the EC2 terminal, or by copying the build-exoctk-env-cpu.sh file directly to the EC2 instance and running it. To do the later option, from your local machine, type:
scp -i <path_to_private_key> build-exoctk-env-cpu.sh ec2-user@<ec2_public_dns>:/home/ec2-user/build-exoctk-env-cpu.sh
ssh -i <path_to_private_key> ec2-user@<ec2_public_dns>
./build-exoctk-env-cpu.sh
Once completed, users may log out of the EC2 instance, as there will no longer be any command-line interaction needed.
Fill out the aws_config.json file¶
Within the atmospheric_retrievals subpackage, there exists an aws_config.json file. Fill in the values for the two fields: ec2_id, and ssh_file. The ec2_id should contain the name of EC2 template ID (which can be found under “Instance ID” in the description of the EC2 instance in the AWS EC2 console), and ssh_file should point to the location of the private SSH file described in the “Create a SSH key pair” section:
{
"ec2_id" : "<ec2_instance_ID>",
"ssh_file" : "<path_to_private_key>"
}
Run some code!¶
Now that we have configured everything to run on AWS, the next step is to simply perform a retrieval! Open a Python session or Jupyter notebook. To invoke the use of the AWS EC2 instance, simply use the use_aws() method before performing the retrieval. A short example is provided below.
import numpy as np
from platon.constants import R_sun, R_jup, M_jup
from exoctk.atmospheric_retrievals.aws_tools import get_config
from exoctk.atmospheric_retrievals.platon_wrapper import PlatonWrapper
params = {
'Rs': 1.19, # Required
'Mp': 0.73, # Required
'Rp': 1.4, # Required
'T': 1200.0, # Required
'logZ': 0, # Optional
'CO_ratio': 0.53, # Optional
'log_cloudtop_P': 4, # Optional
'log_scatt_factor': 0, # Optional
'scatt_slope': 4, # Optional
'error_multiple': 1, # Optional
'T_star': 6091} # Optional
pw = PlatonWrapper()
pw.set_parameters(params)
pw.fit_info.add_gaussian_fit_param('Mp', 0.04*M_jup)
pw.fit_info.add_uniform_fit_param('Rp', 0.9*(1.4 * R_jup), 1.1*(1.4 * R_jup))
pw.fit_info.add_uniform_fit_param('T', 300, 3000)
pw.fit_info.add_uniform_fit_param("logZ", -1, 3)
pw.fit_info.add_uniform_fit_param("log_cloudtop_P", -0.99, 5)
wavelengths = 1e-6*np.array([1.119, 1.1387])
pw.bins = [[w-0.0095e-6, w+0.0095e-6] for w in wavelengths]
pw.depths = 1e-6 * np.array([14512.7, 14546.5])
pw.errors = 1e-6 * np.array([50.6, 35.5])
ssh_file = get_config()['ssh_file']
ec2_id = get_config()['ec2_id']
pw.use_aws(ssh_file, ec2_id)
pw.retrieve('multinest')
pw.save_results()
pw.make_plot()
Output products¶
Executing the above code will result in a few output files:
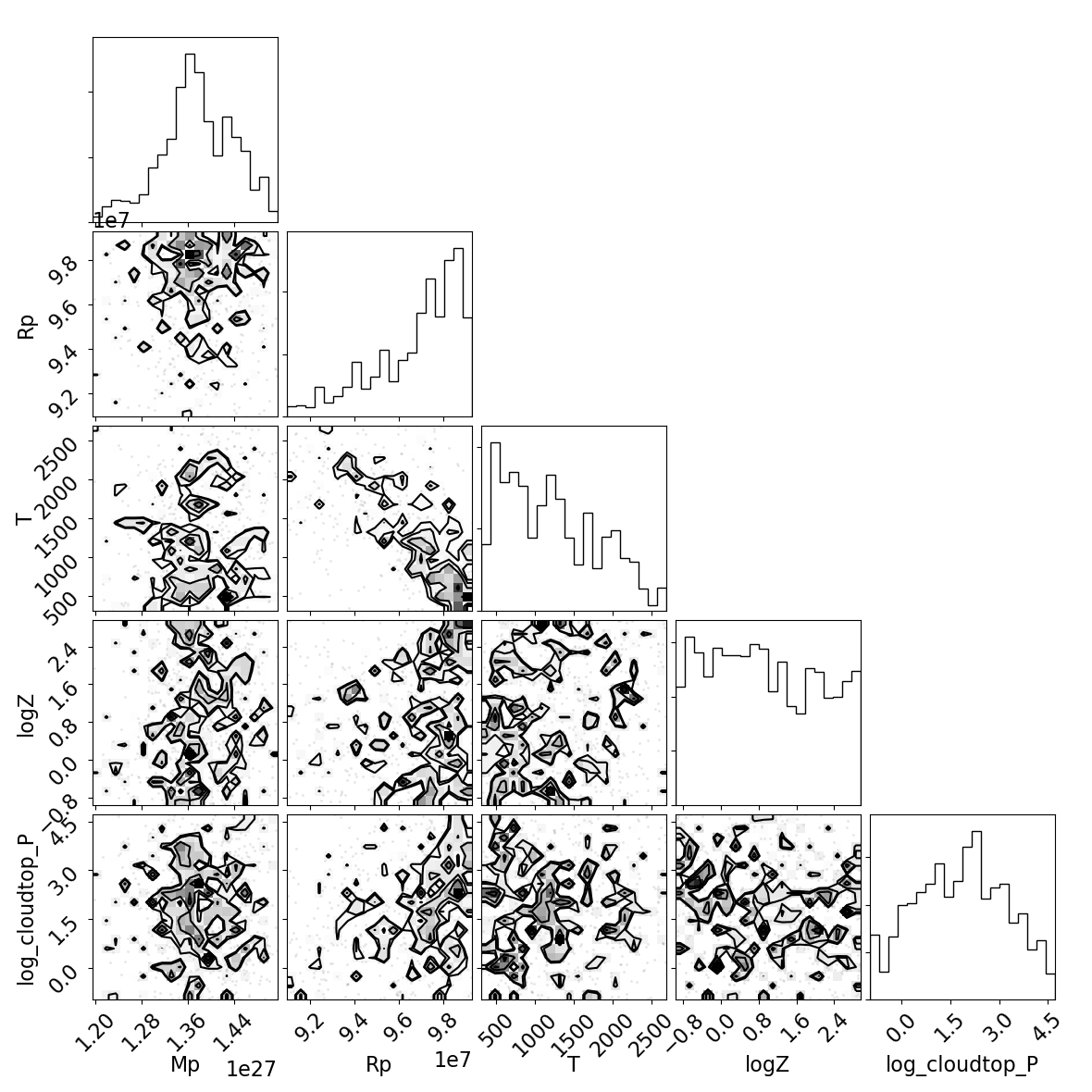
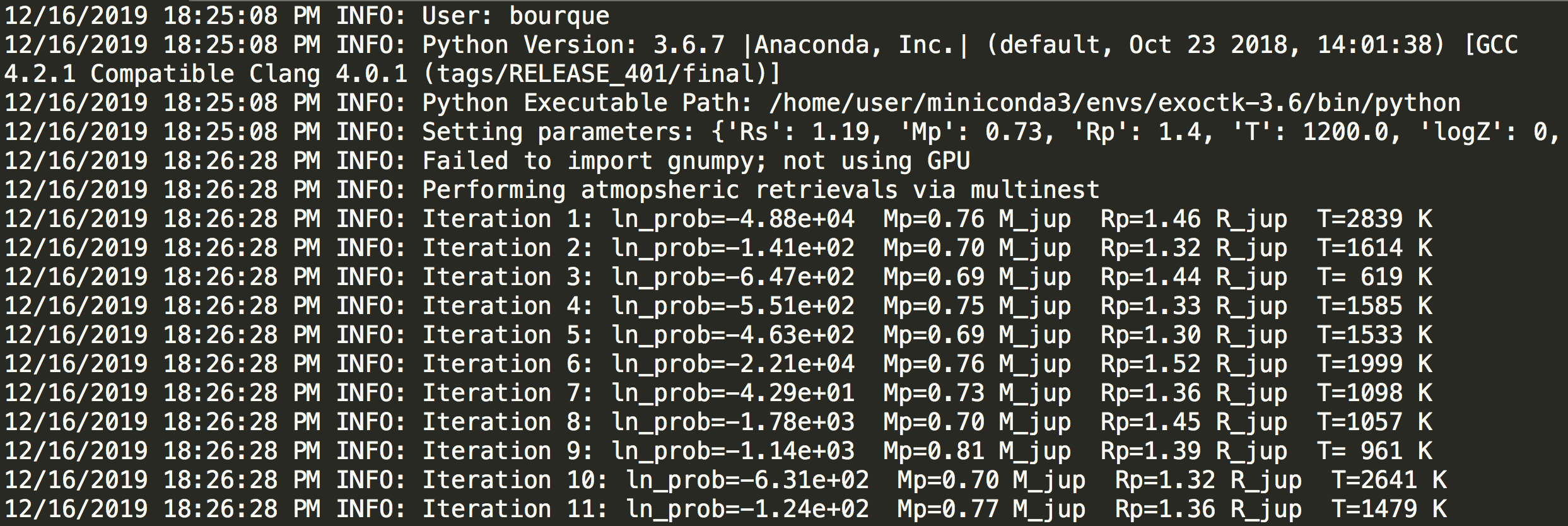
YYYY-MM-DD-HH-MM.log- A log file that captures information about the execution of the code, including software environment information, EC2 start/stop information, retrieval information and results, and total computation time.multinest_results.dat/emcee_results.obj- A data file containing the best fit results of the retrieval. Note thatemceeresults are saved as a Python object and saved to an object file.<method>_corner.png- A corner plot describing the quality of the best fit results of the retrieval, where<method>is the method used (i.e.multinestoremcee)
Here is an example of what these output products may look like:
Corner plot:
Results file:

Log file:
A final note: Make sure to terminate unused EC2 instances, or else Amazon will keep charging you!¶
Jeff Bezos does not need any more of your money. To terminate an EC2 instance, go to the EC2 console, then the “Instances” page. Select the instance of interest, click “Actions”, “Instance State”, then “Terminate”.
Using a GPU-enabled EC2 instance¶
The atmospheric_retrieval subpackage supports the use of GPU-enabled EC2 instances. Users may create a GPU-enabled AMI/instance type configuration, such as AMI ami-0c322300a1dd5dc79 with instance type p3.2xlarge, which contains multiple GPUs. However, the process for building a GPU-enabled exoctk software environment is more complex than that is described in the “Build the exoctk software environment on the ec2 instance” section, as it involves multiple machine reboots and thus cannot be easily installed by running a single bash script.
Below are instructions for installing/configuring the software environment needed for the GPU-enabled EC2 instance. These commands are also provided in the atmospheric_retrievals/build-exoctk-env-gpu.sh file.
First create a GPU-enabled EC2 instance, as described above and in the “Launch an EC2 instance” section.
Once the EC2 instance is created, navigate back to the AWS EC2 console and select “Instances” on the left side of the page to see a list of EC2 instances. Users should see the EC2 instance that was just created.
Allow the EC2 instance to enter the “Running” phase for a minute or two. Then, connect to the machine via the command line, as described in the “Build the
exoctksoftware environment on the EC2 instance” section.Once logged into the machine, users can now begin to run the necessary installation commands, provided below:
// Install NVIDIA GPU Driver
sudo yum -y update
sudo yum -y install wget nano elfutils-libelf-devel
sudo yum -y groupinstall "Development Tools"
sudo sed -i 's/crashkernel=auto"/crashkernel=auto nouveau.modeset=0"/g' /etc/default/grub
sudo grub2-mkconfig -o /boot/grub2/grub.cfg
sudo touch /etc/modprobe.d/blacklist.conf
sudo chmod 777 /etc/modprobe.d/blacklist.conf
sudo echo 'blacklist nouveau' > /etc/modprobe.d/blacklist.conf
sudo mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r)-nouveau.img
sudo dracut /boot/initramfs-$(uname -r).img $(uname -r)
sudo reboot
Allow EC2 to reboot, then when the EC2 is running again, log back into the instance.
sudo systemctl isolate multi-user.target
wget http://us.download.nvidia.com/XFree86/Linux-x86_64/430.40/NVIDIA-Linux-x86_64-430.40.run
sudo sh NVIDIA-Linux-x86_64-430.40.run
// Choose "No" when prompted to install 32-bit
sudo reboot
Again, allow EC2 to reboot, then when the EC2 is running again, log back into the instance.
// Install CUDA Toolkit
wget http://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.243_418.87.00_linux.run
sudo sh cuda_10.1.243_418.87.00_linux.run
// Unselect
export PATH=$PATH:/usr/local/cuda-10.1/bin
export LD_LIBRARY_PATH=/usr/local/cuda-10.1/lib64
// Install Anaconda
curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
chmod 700 ./Miniconda3-latest-Linux-x86_64.sh
bash ./Miniconda3-latest-Linux-x86_64.sh -b -p $HOME/miniconda3
// Set important environment variables
export PATH=/home/ec2-user/miniconda3/bin:$PATH
export EXOCTK_DATA=''
// Create base CONDA
conda create --yes -n exoctk-3.6 python=3.6 git numpy flask pytest
conda init bash
source ~/.bashrc
conda activate exoctk-3.6
// Install ExoCTK package and conda environment
git clone https://github.com/ExoCTK/exoctk.git
cd exoctk/
conda env update -f env/environment-3.6.yml
conda init bash
source ~/.bashrc
conda activate exoctk-3.6
python setup.py develop
cd ../
// Install jwst_gtvt
rm -fr /home/ec2-user/miniconda3/envs/exoctk-3.6/lib/python3.6/site-packages/jwst_gtvt
git clone https://github.com/spacetelescope/jwst_gtvt.git
cd jwst_gtvt
git checkout cd6bc76f66f478eafbcc71834d3e735c73e03ed5
python setup.py develop
cd ../
// Install additional libraries
pip install bibtexparser==1.1.0
pip install corner==2.0.1
pip install lmfit==0.9.13
pip install platon==3.1
// Install cudamat
git clone https://github.com/cudamat/cudamat.git
sudo sed -i "s/-O',/-O3',/g" /home/ec2-user/cudamat/setup.py
cd cudamat
python setup.py develop
cd ../
// Install gnumpy
git clone https://github.com/ExoCTK/gnumpy3.git
cd gnumpy3
python setup.py develop
cd ../
// Build skeleton EXOCTK_DATA directory
mkdir exoctk_data/
mkdir exoctk_data/exoctk_contam/
mkdir exoctk_data/exoctk_log/
mkdir exoctk_data/fortney/
mkdir exoctk_data/generic/
mkdir exoctk_data/groups_integrations/
mkdir exoctk_data/modelgrid/
// Print the complete environment
conda env export
Now that the EC2 instance is configured, select the EC2 instance in the AWS console and select “Actions > Stop” to stop the instance. Paste the EC2 instance ID into the ec2_id key in the aws_config.json file to point to the instance for processing.
At this point, users may now run code like the example in the “Run some code!” section, but now retrievals will be performed on the GPU-enabled EC2 instance.